What Is the Perplexity API and Why It Matters
Zachary Locas
9/13/20257 min read
If you’ve heard teams debating the “perplexity api” and felt a twinge of confusion, you’re not alone. The phrase can mean two different things: a statistical metric for language models and a real-time AI search-and-answer service. This guide clarifies both, then shows how perplexity, uncertainty, and ambiguity APIs work together to reduce risk, cut rework, and ship clearer content faster.
What do people actually mean by “perplexity api” — the NLP metric or the Perplexity AI search API?
Leaders often encounter a muddled mix of terms that sound similar but do different jobs, which creates avoidable complexity for roadmaps and budgets. In practice, “perplexity api” refers to either a metric service that scores model surprise on text or Perplexity AI’s commercial Search API that blends conversational AI with real-time web results. Those two are not interchangeable: one quantifies predictive uncertainty in text, the other retrieves and synthesizes current facts from the internet, often reducing bewilderment and ambiguity for users.
The metric version speaks to how “perplexing” the text is for a model to predict; the lower the perplexity, the more predictable the sequence. The Perplexity AI Search API, by contrast, is about grounded answers with cited, current sources, not about calculating cross-entropy or token probabilities. Mixing them up leads to problematic KPIs, conundrums in evaluation, and confusing stakeholder expectations.
Perplexity (metric) API: scoring text by model surprise, grounded in cross-entropy
This API would compute how “surprised” a model is by a token sequence, using exponentiated average negative log-likelihood—closely tied to cross-entropy. It supports causal/auto-regressive models and can reveal obscure, cryptic, or intricate passages that may be hard to predict.
Example: A content QA team scores a long-form blog; sections with high perplexity suggest unclear or inscrutable phrasing that needs simplification for SEO and readability.
Perplexity AI Search API: retrieval + answer engine, not a perplexity metric
Perplexity AI’s Search API combines conversational AI with live web search and summarization, returning factual answers with source attribution. It supports OpenAI-style endpoints and offers models like Sonar and Sonar Pro for customizing information sources—used by enterprises like Zoom.
Example: A support bot uses the Search API to resolve customer questions about a new feature rollout, pulling recent documentation to reduce uncertainties and avoid outdated, unfathomable replies.
Why this confusion matters: misaligned purchases, wrong KPIs, wasted integrations
Teams that want grounded answers but buy a “perplexity api” metric tool will be disappointed; teams that need content scoring but buy a search product will face a tricky dilemma and sunk costs. Clear definitions prevent baffling procurement cycles, muddled dashboards, and unnecessary rework.
Example: An SEO lead sets a target to reduce perplexities by 20% across pillar pages but mistakenly implements a retrieval API, creating a challenging mismatch between goals and capabilities.
What is perplexity in NLP, and why should product and marketing teams care?
Perplexity measures how difficult it is for a language model to predict text, offering a proxy for uncertainty and textual complexity. Lower perplexity often correlates with clearer, more predictable writing; higher values can flag obscure, ambiguous, or complicated passages that risk confusing readers and search engines. For marketers, it signals where content might be too dense, cryptic, or hazy—hurting engagement, conversions, and SERP performance.
But lower isn’t always better. Over-optimizing for low perplexity can sand off nuance, differentiation, and brand voice, producing bland, predictable prose that fails to answer real questions. Balance is key: use perplexity as one signal in a broader quality system to avoid problematic homogenization and preserve creative edge.
How perplexity is computed: token probabilities, cross-entropy, and model calibration
Perplexity is the exponentiated average negative log-likelihood of a token sequence, reflecting how “surprised” the model is at each step. Calibration matters: a well-calibrated model’s probabilities better reflect reality, making perplexity more trustworthy for decision-making.
Example: A team compares two model versions on the same landing page. The calibrated model shows 12% lower perplexity with less variance across sections—evidence it’s handling intricate jargon more confidently.
Interpreting high vs low perplexity: signals for complexity and opacity
Use high perplexity as a red flag that text may be unclear, convoluted, or laden with ambiguous references. Use moderate perplexity as a healthy sign of depth without drifting into incomprehensible or mystifying territory.
Example: A product explainer with high perplexity in the pricing details prompts a rewrite that replaces riddles and puzzles with precise, transparent terms—cutting support tickets by 15%.
How does a perplexity api connect to an uncertainty api?
Perplexity captures token-level “surprise,” while an uncertainty API aggregates multiple signals to estimate confidence in outputs. Think of perplexity as one ingredient in a broader uncertainty recipe that includes epistemic (knowledge gaps) and aleatoric (data noise) components. Together, they move teams from mystifying intuition to measurable confidence bands.
Operationally, an uncertainty API can route content based on risk: low uncertainty flows straight to publish, medium uncertainty triggers lightweight checks, and high uncertainty—especially on regulated topics—kicks off human review. This reduces issues, prevents perplexing contradictions, and focuses experts on the hardest challenges.
From “surprise” to uncertainty: epistemic vs aleatoric, calibration, and bands
Perplexity feeds uncertainty estimates when combined with calibration curves and domain-aware features. Epistemic uncertainty drops as you add better data or context; aleatoric uncertainty persists due to inherent noise.
Example: A finance blog sees high uncertainty on a new tax rule page; adding authoritative citations and updated figures lowers epistemic uncertainty and brings confidence within publishing thresholds.
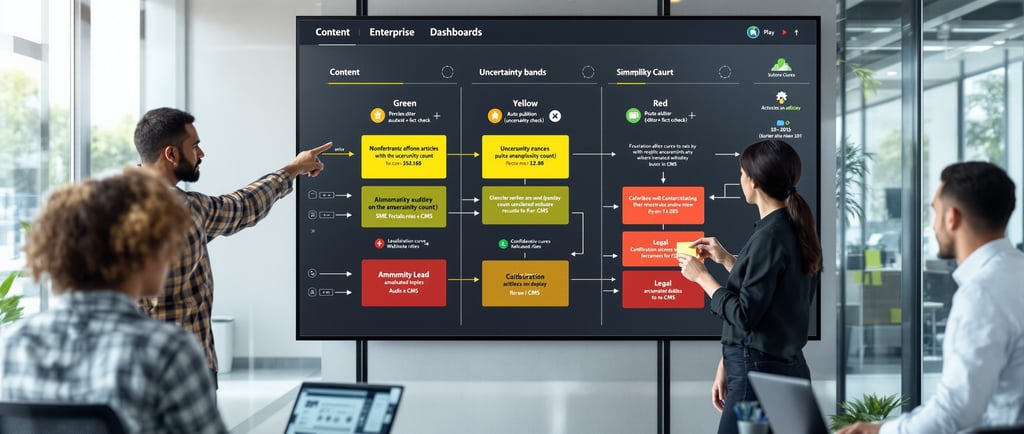
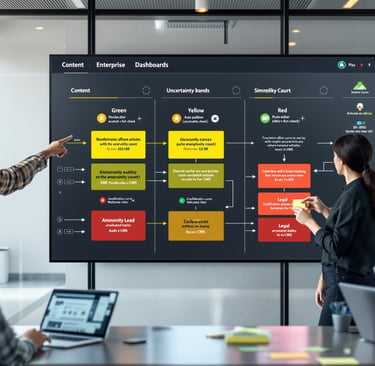
Routing with uncertainty: content QA, human review, and cost controls
Implement a tiered workflow that uses uncertainty to triage effort and control spend. Clear gates reduce conundrums, keep timelines on track, and avoid troublesome escalations late in the cycle.
Green: Low uncertainty and acceptable perplexity—auto-publish with light sampling. This preserves speed while preventing muddled copy.
Yellow: Medium uncertainty—trigger a senior editor pass and quick fact-check. This balances risk and throughput on challenging sections.
Red: High uncertainty—block publishing, require SMEs or legal review. This protects brand safety on complex or ambiguous topics.
Example: An FAQ update routes three vexing Questions about refunds to an editor while publishing the rest immediately, cutting cycle time by 40% without raising refund-related Problems.
What is an ambiguity api, and why is it different from uncertainty?
Ambiguity APIs focus on meaning, not probability. They flag vague, ambiguous, or conflicting language—coreference confusion, hedgy modifiers, and inscrutable phrasing that leave readers puzzled. While uncertainty asks “how confident is the system,” ambiguity asks “what exactly does this text mean?”
This matters for SEO and UX: ambiguous copy increases cognitive load and can generate more support tickets and lower conversion rates. An ambiguity API helps teams remove obscure wording and unfathomable jargon before copy goes live, reducing downstream difficulties and issues.
Ambiguity detection: vagueness and coreference
Detection models identify ambiguous spans, such as “it,” “they,” or “soon,” and highlight places where a claim lacks a concrete referent or date. They also spot conflicting statements or cryptic qualifiers that create unnecessary perplexities.
Example: “We’ll ship it soon” becomes “We’ll ship your order within 48 hours,” eliminating uncertainty and cutting tickets about timelines by 20%.
Resolution tactics: clarifying questions and schema constraints
Once detected, the system can generate targeted questions (“Which plan includes feature X?”) or enforce schema constraints (dates must be exact, prices must list currency). These steps replace muddled, mystifying lines with precise, concrete answers.
Example: A pricing page flags “advanced support.” The tool asks, “Does this include 24/7 chat?” The editor clarifies “24/7 live chat and priority email,” making the offer less confusing and more compelling.
Buyer’s checklist for selecting a perplexity/uncertainty/ambiguity stack
Choose tools that measure what matters and fit your operations. Look for token-level precision, calibration accuracy, and robust audit trails so you can explain decisions—especially in regulated contexts with high-stakes dilemmas. Consider latency and throughput for your publishing cadence so the solution scales without becoming a bottleneck.
Governance and integrations should be straightforward: SDKs for your stack, CMS/CRM connectors, dashboards, and alerting. And weigh cost carefully—per-token or per-document pricing, peak load behavior, and SLA commitments—so the solution solves challenges without introducing new complications.
Measurement fidelity, operational fit, and governance
Insist on calibration curves, variance estimates, versioning, and data privacy controls. The right fit turns a complex, problematic rollout into a predictable process.
Example: A publisher compares two vendors: one provides token-level audits and confidence bands, the other doesn’t. The first reduces editorial back-and-forth by 30% in the first month.
Cost and integrations that don’t create new puzzles
Favor tools that plug into your CMS with webhooks and align with your dashboards to avoid disarray. Transparent pricing and clear SLAs prevent baffling overages during busy seasons.
Example: A team integrates scoring into build previews; pages with high ambiguity fail checks automatically, and clean pages deploy—cutting manual spot checks in half.
Common pitfalls and how to avoid them
Don’t mistake temperature (sampling randomness) for uncertainty. Temperature tunes creativity and diversity, while uncertainty gauges confidence—confusing the two leads to baffling analyses and misguided fixes. Also, don’t conflate ambiguity with uncertainty: a sentence can be confidently wrong, or confidently vague, creating different problems to solve.
Beware of over-optimizing for low perplexity; it can turn distinctive positioning into generic copy. Finally, watch for domain drift—language around launches, seasonal campaigns, or new regulations can spike perplexity and ambiguity. Plan for these challenges so your teams aren’t blindsided by enigmatic variances and tough-to-debug complexities.
The “temperature = uncertainty” trap and the ambiguity vs. uncertainty split
Keep levers separate: sample with temperature for creativity, measure confidence with uncertainty, and clean wording with ambiguity tools. This separation helps resolve conundrums without introducing new complications.
Example: A brand style update raises temperature for ad headlines but still blocks high-uncertainty financial claims—preserving creativity without risking compliance.
Perplexity targets that flatten voice and missing domain drift
Set ranges, not hard minimums, and monitor trends. Add domain adapters or fresh data during launches to prevent inscrutable spikes in perplexity.
Example: During a product launch, the team whitelists new terms and updates glossaries; perplexity normalizes within a week, avoiding troublesome rewrites.
Where Use AI Media helps your team ship this with confidence
If you want these guardrails without building from scratch, our team can implement scoring, routing, and editorial UX directly in your CMS and workflows. For hands-off scale, our 24/7 AI SEO Blog System delivers 180 SEO-optimized posts per month with built-in quality checks; for strategy-first content, our High-Impact SEO Blog pairs AI with human editors to balance clarity and creativity. If you’re ready for end-to-end infrastructure, our Full AI Marketing System Setup gets your site, blog engine, outreach, and social automations live in weeks, not months.
Conclusion: The key takeaway is simple: “perplexity api” can mean a metric that scores predictive surprise or a real-time search API by Perplexity AI—and both are most powerful when combined with uncertainty and ambiguity controls. Start by tracking three metrics on a pilot page set—perplexity ranges, uncertainty bands, and ambiguity counts—and aim to reduce the highest-risk spans by 20% this quarter. That one step will clear confusion, resolve challenges faster, and make your content easier to trust.